Deriving ABR from Naturalistic Sounds
May 2025
The auditory brainstem response (ABR) is a powerful tool for probing early neural processing of sound, but it has traditionally required repetitive, artificial stimuli like clicks or tone bursts. This project asks: can we reliably measure ABRs from the rich, complex sounds people actually hear every day — speech and music? And if so, does the brainstem treat these two fundamental sound classes differently?
The answer turns out to be surprising: the human brainstem encodes music and speech in nearly the same way. Despite the vast acoustic differences between music and speech — their distinct spectral profiles, temporal modulations, and amplitude statistics — subcortical responses to the two are strikingly alike. The divergence between music and speech processing only emerges higher up, at the cortical level. This finding was only possible because we developed a new, physiologically grounded method for deriving ABRs from any naturalistic sound.
We addressed this across two studies that together introduce the new analysis method, establish the subcortical similarity of music and speech encoding, and provide practical guidance for the field.
Part I: A new method reveals subcortical encoding is sound-class invariant
Previous deconvolution approaches used the half-wave rectified stimulus (HWR) as a regressor, which worked for speech but produced poor or absent ABRs for music. We developed a new approach using the auditory nerve modeled (ANM) firing rate — generated from a detailed computational model of the auditory periphery — as the regressor for deconvolution. This physiologically grounded regressor accounts for the complex nonlinearities that occur in early auditory processing before the signal reaches the brainstem.
Key Findings
- The ANM regressor produced clear, canonical ABR waveforms (waves I, III, and V) for both music and speech — a first for naturalistic music.
- Music- and speech-evoked ABRs were strikingly similar (noise-adjusted r = 0.95), demonstrating that subcortical encoding of acoustics is largely independent of sound class.
- At the cortical level, the ANM regressor also increased the similarity of music and speech responses compared to traditional envelope-based analysis, but meaningful differences persisted — suggesting that stimulus-class-dependent processing emerges at the cortical, not subcortical, level.
- The ANM regressor yielded significantly better prediction accuracy and spectral coherence than the HWR regressor for both music and speech.
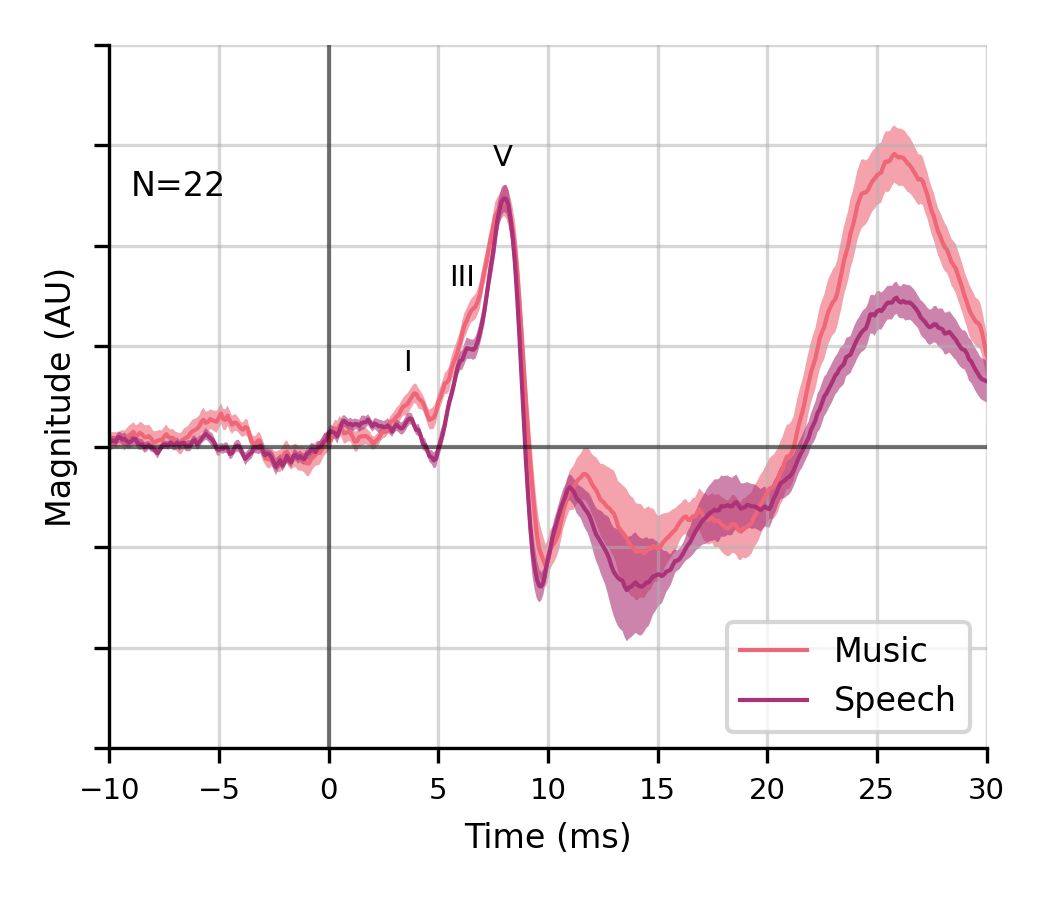
Shan, T., Cappelloni, M.S. & Maddox, R.K. Subcortical responses to music and speech are alike while cortical responses diverge. Scientific Reports 14, 789 (2024). https://doi.org/10.1038/s41598-023-50438-0
Data: OpenNeuro | Code: GitHub
Part II: Which method should you use?
With multiple deconvolution-based methods now available for deriving ABRs from continuous speech, we conducted a comprehensive head-to-head comparison of three regressors — HWR, glottal pulse train (GP), and ANM — evaluated on both unaltered natural speech and re-synthesized "peaky" speech.
Key Findings
- The ANM regressor provided the best overall performance: highest signal-to-noise ratio, best prediction accuracy, and superior spectral coherence across conditions.
- ANM achieved robust ABRs (SNR > 0 dB) for all subjects within ~6 minutes of recording, compared to 12 min for GP and 35+ min for HWR — making it roughly 6x faster than the conventional approach.
- The ANM regressor revealed early ABR components (waves I and III) in addition to wave V, without requiring specialized stimulus preprocessing or aggressive filtering.
- The GP regressor paired with peaky speech also performed well, offering the advantage of responses expressed in interpretable voltage units.
- The study provides practical guidance: ANM is recommended as the default for naturalistic-sound ABR research; GP is a strong alternative when peaky speech is feasible and interpretable units are desired.
Shan, T. & Maddox, R.K. Comparing methods for deriving the auditory brainstem response to continuous speech in human listeners. Imaging Neuroscience 3 (2025). https://doi.org/10.1162/IMAG.a.19
Code: GitHub